You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Dyescape - Where Adventures Begin
New Beginnings - v0.2 Alpha Release
PIN
- 11,728
- 3
Alpha Release
We are releasing the second iteration of the Alpha, version 0.2! The evolution of this update is immense and I would like to discuss a few. The teaser with release date will be linked below so you can skip ahead if you want.
We are releasing the second iteration of the Alpha, version 0.2! The evolution of this update is immense and I would like to discuss a few. The teaser with release date will be linked below so you can skip ahead if you want.

Initial Plan
The initial plan of the v0.2 update was to populate the forest and the mining region. Moreover, it would feature a class release and plan to fulfil promised donator features such as banking space. Quality of life fixes would be performed by software changes and more quests would be added to the aforementioned region. The level cap would have been expanded by five levels and we would call it a day. The tally would be around 20 tickets for the content team to tackle and about 50 for its software counter part. All looked well, we tackled feedback and addressed it. But one comment...
Recent outages
PIN
- 8,938
- 0
Dear community, as some of you may have noticed, we've suffered from several infrastructure outages over the recent weeks. This caused our website, Minecraft servers and internal tooling to be unavailable. We wish to be transparent with everyone on what is going on, why these outages happened and how we plan to tackle them moving forward. The post below will involve some technical details. You can skip to the summary at the bottom for a short, simplified version.
Storage
Within the hosting, and especially the cloud hosting industry, storage comes in many different shapes, sizes, pros and cons. Some setups value simplicity, some value scalability, others value performance or integrity. When setting up our infrastructure, we had to choose between these options and decided to go with a storage solution that had integrity and was scalable. As such, we are running an internal block storage solution called Longhorn, with volume replication across all of our servers...
Storage
Within the hosting, and especially the cloud hosting industry, storage comes in many different shapes, sizes, pros and cons. Some setups value simplicity, some value scalability, others value performance or integrity. When setting up our infrastructure, we had to choose between these options and decided to go with a storage solution that had integrity and was scalable. As such, we are running an internal block storage solution called Longhorn, with volume replication across all of our servers...
v0.1.0 - Release analysis & reflection
PIN
- 11,601
- 6
After a tremendously long development period, Dyescape has finally been able to put out a first release; v0.1.0. Those who were active in the Discord or the Twitch livestream yesterday will have already seen that we ran into a few technical struggles. This thread serves as transparency towards the community to explain what happened, why it happened, how it could happen and what has been done to address it. On a positive note, we'll also list a few technical things that did go well.
Database cluster
In a project like this, being dynamic with content changes is crucial. Software and content are two completely separate complexities, and in order to ensure that it doesn't become a single, even larger complexity, we've made everything configurable. From items, to skills, creatures, quests, random encounters; everything is configurable. In order to facilitate for this, a JSON document based file storage system was set up. For the past years during development, this...
Database cluster
In a project like this, being dynamic with content changes is crucial. Software and content are two completely separate complexities, and in order to ensure that it doesn't become a single, even larger complexity, we've made everything configurable. From items, to skills, creatures, quests, random encounters; everything is configurable. In order to facilitate for this, a JSON document based file storage system was set up. For the past years during development, this...
It's time, the release is known.
PIN
- 11,002
- 2
Alpha
While some still cannot believe it, we are actually launching on the 7th of August! Note that there are only limited alpha slots available. Sign up before it's too late. And join the discord to receive all kinds of unique sneak-peeks!

Thank you for the image, Trook.
While some still cannot believe it, we are actually launching on the 7th of August! Note that there are only limited alpha slots available. Sign up before it's too late. And join the discord to receive all kinds of unique sneak-peeks!
Thank you for the image, Trook.
Have you seen our alpha teaser yet?
Alpha Teaser, Class Descriptions, and Percentages.
PIN
- 8,781
- 0
Alpha Release Date
The ancient old question; when will Dyescape release? The wait is soon over. Please read the post below and sit tight for just a little longer!

Alpha Teaser
While some still cannot believe it, we are actually launching! On the 17th of July, we are releasing an alpha teaser. Note that there are only limited alpha slots available. Sign up before it's too late.
The ancient old question; when will Dyescape release? The wait is soon over. Please read the post below and sit tight for just a little longer!
The entrance of Clemens, located on Phala.
Alpha Teaser
While some still cannot believe it, we are actually launching! On the 17th of July, we are releasing an alpha teaser. Note that there are only limited alpha slots available. Sign up before it's too late.
The percentage, slots, and performance testing
PIN
- 11,257
- 5
Hello! It's been a while since we posted here. Let's catch up shall we?
Alpha Release Date
The ancient old question; when will Dyescape release? Well, for the first time we will shed some light on this and make you a promise. The release will happen in 2021. But one might say that this does not indicate much. Well, no it does not. Therefore, we introduced 'the percentage'.

Clemen's Graveyard; playable region within AlphaThe Percentage
This percentage shows the ratio open tickets vs closed tickets. These tickets are not weighted, which means that the percentage could...
Alpha Release Date
The ancient old question; when will Dyescape release? Well, for the first time we will shed some light on this and make you a promise. The release will happen in 2021. But one might say that this does not indicate much. Well, no it does not. Therefore, we introduced 'the percentage'.
If you're looking for the alpha applications (takes 2 min) click here!
Clemen's Graveyard; playable region within Alpha
This percentage shows the ratio open tickets vs closed tickets. These tickets are not weighted, which means that the percentage could...
Progression, streams and MQL!
PIN
- 11,402
- 4
Greetings to you!
If you're looking for the alpha applications (takes 2 min) click here!
Progression and Streams
As a few people have noticed by now... We are progressing! But, but... You already made a progression post as well previously. yes, indeed, I did! However, this time it's different. You can actively see the progression through our live streams! Do be sure to follow my personal twitch account (this is where I stream implementation of Dyescape) here and follow the official Dyescape twitch here. Hope to see you soon!
If you're looking for the alpha applications (takes 2 min) click here!
Progression and Streams
As a few people have noticed by now... We are progressing! But, but... You already made a progression post as well previously. yes, indeed, I did! However, this time it's different. You can actively see the progression through our live streams! Do be sure to follow my personal twitch account (this is where I stream implementation of Dyescape) here and follow the official Dyescape twitch here. Hope to see you soon!

The weekend was incredibly productive and this an item* was born.
All of the previous streams can be...Giveaway responses, Game night and more content
PIN
- 10,292
- 4
G'day everyone!
Giveaway responses
I'll jump right in with some statistics about the giveaway.
...We had exactly 100 entries spread out over all 7 questions.
Community response summarized for every question:
Question 1: "What do you hope to get out of Dyescape"?
This one basically boiled down to a new and unique MMORPG which they can play on with friends and the community.
Question 2: "What are you most excited for out of all of Dyescape?"
This one went all over the place. So a few top mentions are: See Dyescape grow/develop, Community interaction, map/content/atmosphere.
Question 3: "What class are you planning on playing? (Knight, Warrior, Mage, Priest)"
A: Warrior: 22.2%
Knight: 11.1%
Priest: 16.7%
Mage: 50%
Question 4: "What feature of any other game do you like the most?"
Again! A lot of varying responses but the one that shone the brightest was overall character progression and customization. Closely followed by a party system...
Giveaway responses
I'll jump right in with some statistics about the giveaway.
...We had exactly 100 entries spread out over all 7 questions.
Community response summarized for every question:
Question 1: "What do you hope to get out of Dyescape"?
This one basically boiled down to a new and unique MMORPG which they can play on with friends and the community.
Question 2: "What are you most excited for out of all of Dyescape?"
This one went all over the place. So a few top mentions are: See Dyescape grow/develop, Community interaction, map/content/atmosphere.
Question 3: "What class are you planning on playing? (Knight, Warrior, Mage, Priest)"
A: Warrior: 22.2%
Knight: 11.1%
Priest: 16.7%
Mage: 50%
Question 4: "What feature of any other game do you like the most?"
Again! A lot of varying responses but the one that shone the brightest was overall character progression and customization. Closely followed by a party system...
Team expansion, donator features and a sweet giveaway
PIN
- 60,509
- 117
Dear community,
I'll barge right in with this post does not contain a release date. As said on the Discord earlier. Sorry! But there's some other sweet news!
There's been a team expansion! Normally we do not announce this formally but this time around it is a developer! Welcome Yannick! We are glad to have you on board!
Recently, we have also released a list of donator features and revamped our shop! If you have any suggestions to rank features please let us know by making a suggestion thread. But then there's on greater thing.
Moreover, we reached 1000 members in our Discord! And because of that, we will be hosting a giveaway. We will be giving out:
- 3x Noble.
- 2x Baron.
- 1x Viscount.
- 1x Duke.
Did you forget what all these ranks do? Visit the shop!
...
I'll barge right in with this post does not contain a release date. As said on the Discord earlier. Sorry! But there's some other sweet news!
There's been a team expansion! Normally we do not announce this formally but this time around it is a developer! Welcome Yannick! We are glad to have you on board!
Recently, we have also released a list of donator features and revamped our shop! If you have any suggestions to rank features please let us know by making a suggestion thread. But then there's on greater thing.
Moreover, we reached 1000 members in our Discord! And because of that, we will be hosting a giveaway. We will be giving out:
- 3x Noble.
- 2x Baron.
- 1x Viscount.
- 1x Duke.
Did you forget what all these ranks do? Visit the shop!
...
We are progressing!
PIN
- 13,809
- 7
Hello soon-to-be Eturians!
If you're looking for the alpha applications (takes 2 min) click here!
We are progressing. What do we mean by this? Well, for the first time in three years (yes three, we can't believe it either) things are getting finalized. What does this mean? We are implementing. Quests are being added, missing features are created, and bugs are being patched. Check out a lovely example below!

But this is all cool and all but how about a release date?
This is a touchy subject but no, we will not be giving out a release date till we are 100% certain we will make it. What does this mean? Once we set one, it's happening. No delays or unfortunate things. It will happen. And we hope you will be there to experience the end of this ride with us. The start of a new beginning. Your adventure awaits.
See you soon.
If you're looking for the alpha applications (takes 2 min) click here!
We are progressing. What do we mean by this? Well, for the first time in three years (yes three, we can't believe it either) things are getting finalized. What does this mean? We are implementing. Quests are being added, missing features are created, and bugs are being patched. Check out a lovely example below!
But this is all cool and all but how about a release date?
This is a touchy subject but no, we will not be giving out a release date till we are 100% certain we will make it. What does this mean? Once we set one, it's happening. No delays or unfortunate things. It will happen. And we hope you will be there to experience the end of this ride with us. The start of a new beginning. Your adventure awaits.
See you soon.
Fabulous 4k wallpapers!
PIN
- 10,267
- 0
Looking to sign up for alpha? Click here!
We went out of our way and handcrafted some gorgeous wallpapers! Okay, enough self-praising. But, you got to admit, they are pretty cool.
Download link (4k): click here

Download link (4k): click here

What has been happening, changelogs and more!
PIN
- 16,417
- 3
Dear fellow soon™-to-be Eturians,
One may ask, what has been happening? Well, the answer is quite simple! We have been working hard! For those who do not know us yet. We are creating an MMORPG in Minecraft. We have been doing it for the past two years and hopefully, we are nearing an alpha release.
One may ask, what has been happening? Well, the answer is quite simple! We have been working hard! For those who do not know us yet. We are creating an MMORPG in Minecraft. We have been doing it for the past two years and hopefully, we are nearing an alpha release.
If you want to stay up to date in real-time, know where we are at with development, please consider joining our discord!

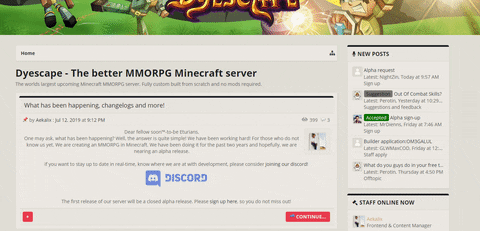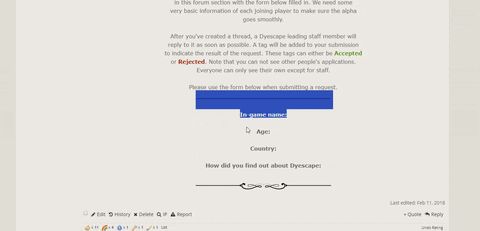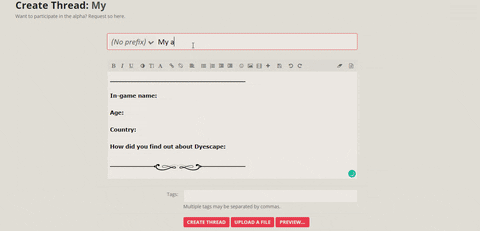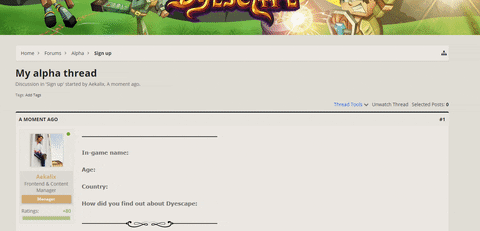
The first release of our server will be a closed alpha release. Please sign up here, so you do not miss out!
The first release of our server will be a closed alpha release. Please sign up here, so you do not miss out!
Instagram Giveaway!
PIN
- 18,482
- 16
Hello, this is the thread to participate in the Instagram giveaway!
If you have not read our post on our discord server then shame on you! You can, however, still read it here:
If you have not read our post on our discord server then shame on you! You can, however, still read it here:
"Dear people, I am a messenger from far far away! I sailed the Blue Graveyard and visited every island along my way to tell you that my beloved king has a something to announce.
I am delighted to announce that after recent fame has fallen upon us we will be giving out wealth. Thou who wins the contest will be given so much gold and silver that they will immediately gain the wealth status of a true nobleman!
But thou may ask where is the contest? What is it? And how can I participate? Well my eager citizens we should first off declare the importance of who can participate! Your king, is a generous king. He is loved by many and hated by none. Not just because he is handsome but because he is kind and someone who favours honour and justice above all. Hence he allows all players and workers to enrol...
I am delighted to announce that after recent fame has fallen upon us we will be giving out wealth. Thou who wins the contest will be given so much gold and silver that they will immediately gain the wealth status of a true nobleman!
But thou may ask where is the contest? What is it? And how can I participate? Well my eager citizens we should first off declare the importance of who can participate! Your king, is a generous king. He is loved by many and hated by none. Not just because he is handsome but because he is kind and someone who favours honour and justice above all. Hence he allows all players and workers to enrol...
Team update
PIN
- 18,544
- 9
Dear community,
It's been a while since we had a positive announcement (other than the glorious mousepad giveaway), but today is a great day for us. No no no, hold your horses, Alpha is not here yet. I'm sorry to crush your hopes and dreams like this already. However, I'm very pleased to announce that we're getting some massive help on the development side. We are expanding the backend team (the nerd team) with not 1, not 2, but 3 new people! Please give a heart warming welcome to @MiniDigger, @MisterErwin and @Michael!
@MiniDigger will be helping me out create more Minecraft plugins. His first job will be something that you're all gonna love; guilds! It's not an easy plugin, but if he's joining the team it means that we can deliver this feature a lot sooner to you guys than originally expected. He already fixed 1 bug in less than 2 hours after I gave him first access, so I have good hopes there...
It's been a while since we had a positive announcement (other than the glorious mousepad giveaway), but today is a great day for us. No no no, hold your horses, Alpha is not here yet. I'm sorry to crush your hopes and dreams like this already. However, I'm very pleased to announce that we're getting some massive help on the development side. We are expanding the backend team (the nerd team) with not 1, not 2, but 3 new people! Please give a heart warming welcome to @MiniDigger, @MisterErwin and @Michael!
@MiniDigger will be helping me out create more Minecraft plugins. His first job will be something that you're all gonna love; guilds! It's not an easy plugin, but if he's joining the team it means that we can deliver this feature a lot sooner to you guys than originally expected. He already fixed 1 bug in less than 2 hours after I gave him first access, so I have good hopes there...
Delay... announcement? [GIVEAWAY]
PIN
- 63,511
- 65
Hello, fellow soon™-to-be Eturians,
I am here with a little announcement - a positive one! No, no. No delay, sorry. I just could not resist it.
But, with that little prank aside, Dyescape has been growing day by day. Either with new team members that actively develope Dyescape or the incredible discord member growth. We are currently at a grand total of 338 members and I find that amazing. The daily activity motivates us more than you probably realise and Dyescape management would like to express our thanks through a giveaway!
We are giving away 3 mousepads.
The only thing you have to do to participate is to leave your favourite Dyescape meme in a reply to this thread. Hint; visit our reddit page (click 'Reddit')! It is stocked with the most creative/s memes! Everybody can participate (including Dyescape staff)!
Note: This is not a meme contest, any dyescape related meme has the same odds in winning. So, just pick...
I am here with a little announcement - a positive one! No, no. No delay, sorry. I just could not resist it.
But, with that little prank aside, Dyescape has been growing day by day. Either with new team members that actively develope Dyescape or the incredible discord member growth. We are currently at a grand total of 338 members and I find that amazing. The daily activity motivates us more than you probably realise and Dyescape management would like to express our thanks through a giveaway!
We are giving away 3 mousepads.
The only thing you have to do to participate is to leave your favourite Dyescape meme in a reply to this thread. Hint; visit our reddit page (click 'Reddit')! It is stocked with the most creative/s memes! Everybody can participate (including Dyescape staff)!
Note: This is not a meme contest, any dyescape related meme has the same odds in winning. So, just pick...
The delays
PIN
- 17,176
- 7
People who are active in our Discord server have already heard the news a few days ago, but we have not posted it here on our website yet. As you might have seen: the alpha has not launched yet. This is simply because we are still behind on schedule in terms of content. Backend (plugins) is roughly on schedule while frontend (buildings & terrain) are even ahead of schedule. The pre alpha has been delayed several times now and it won't be the last one. We apologize for this, but it's reality, and we can't make it any better. We are trying our hardest to get the pre alpha open as soon as possible, but we cannot launch an incomplete game. Our apologies for this.
Note that applications for the content team are still open. Please send some of your work to [email protected] as we are always looking to expand the team with high quality people.
When is the new deadline for the alpha? For the sake of letting this project run smoothly; there isn't one for a while. The...
Note that applications for the content team are still open. Please send some of your work to [email protected] as we are always looking to expand the team with high quality people.
When is the new deadline for the alpha? For the sake of letting this project run smoothly; there isn't one for a while. The...
Delays...
PIN
- 17,092
- 8
As some of you might have already seen in our Discord server, we ran into a few critical issues in terms of plugins and configuration last weekend, causing somewhat delay again on development. On top of this, we are not yet happy with the amount of content we have. We deeply apologize, but we will have to delay the pre-alpha launch by another 2 weeks, putting the new deadline at March 16th.
We do not like the delays either; in fact, we hate delaying it, but we want to live up to the expectations of people and assure a certain level of quality that each and everyone of you deserves. Dyescape is becoming the worlds largest MC MMORPG ever created from the looks of it (in terms of map size, amount of planned content and plugin complexity), and we've only been in development for a good year. Compared to other, similar servers, that is blazingly fast and I am proud to have a dedicated team working hard on this project every day. In our Discord server, we have a highly active...
We do not like the delays either; in fact, we hate delaying it, but we want to live up to the expectations of people and assure a certain level of quality that each and everyone of you deserves. Dyescape is becoming the worlds largest MC MMORPG ever created from the looks of it (in terms of map size, amount of planned content and plugin complexity), and we've only been in development for a good year. Compared to other, similar servers, that is blazingly fast and I am proud to have a dedicated team working hard on this project every day. In our Discord server, we have a highly active...
Pre-alpha slightly delayed
PIN
- 21,196
- 17
Hello everyone,
Due to some drawbacks we experienced last week, we got behind schedule slightly and we cannot get preperations done in the 16th of February. We apologize for this, but like we said in our previous delay, quality is everything for us. We will not release our server if it simply isn't ready yet. Rest assured, this delay isn't as extreme as the last one. The current delay is a delay of 2 weeks, and our new deadline is scheduled on March 2nd.
We are already working on expanding the team to speed up development. So far we have gotten several extra builders, a new content developer and another software developer. If you think you can be useful aspect to our team, don't hesitate to contact us.
We apologize again for the delay, but it is necesarry for us. We will try to release a new gameplay trailer around the 16th of February instead.
~ Dyescape team
Due to some drawbacks we experienced last week, we got behind schedule slightly and we cannot get preperations done in the 16th of February. We apologize for this, but like we said in our previous delay, quality is everything for us. We will not release our server if it simply isn't ready yet. Rest assured, this delay isn't as extreme as the last one. The current delay is a delay of 2 weeks, and our new deadline is scheduled on March 2nd.
We are already working on expanding the team to speed up development. So far we have gotten several extra builders, a new content developer and another software developer. If you think you can be useful aspect to our team, don't hesitate to contact us.
We apologize again for the delay, but it is necesarry for us. We will try to release a new gameplay trailer around the 16th of February instead.
~ Dyescape team
Pre-alpha soon & what to expect
PIN
- 12,244
- 2
Hello everyone,
Just a friendly reminder that we are opening our pre-alpha on the 16th of February, 2018. The exact time is yet to be announced. Also a reminder that the pre-alpha is closed access only to those who have signed up and have been approved. Please create your own pre-alpha access request here.
What is it for:
We would also like to mention what the pre-alpha is, what it is for and what to expect from it. Dyescape is an enormous project, and development has lasted almost 2 years for some of us. This pre-alpha is to prepare for further development and continuation of the project. In the pre-alpha we want to show off some of our early must-have features and we need to test those for bugs and stability. It is also a time where we would request feedback from the community so we can actively adapt to it early on.
This also means that you sign up for the alpha with the intention of helping us out improving the...
Just a friendly reminder that we are opening our pre-alpha on the 16th of February, 2018. The exact time is yet to be announced. Also a reminder that the pre-alpha is closed access only to those who have signed up and have been approved. Please create your own pre-alpha access request here.
What is it for:
We would also like to mention what the pre-alpha is, what it is for and what to expect from it. Dyescape is an enormous project, and development has lasted almost 2 years for some of us. This pre-alpha is to prepare for further development and continuation of the project. In the pre-alpha we want to show off some of our early must-have features and we need to test those for bugs and stability. It is also a time where we would request feedback from the community so we can actively adapt to it early on.
This also means that you sign up for the alpha with the intention of helping us out improving the...
Christmas time
PIN
- 12,232
- 1
It's that time of the year again: Christmas. Everyone from the team here wishes all of you a wonderful Christmas! Hopefully Santa has brought you everything you wished for.
As for a quick development update:
We are putting things together in terms of plugins, maps, buildings and content and we are taking great shape. We will be releasing a new trailer in the upcoming few weeks.
~Dyescape
As for a quick development update:
We are putting things together in terms of plugins, maps, buildings and content and we are taking great shape. We will be releasing a new trailer in the upcoming few weeks.
~Dyescape